Hibernate en detail
Hibernate, ein Framework für Java, ermöglicht neben der Speicherung von gewöhnlichen Objekten in relationalen Datenbanken auch die Abbildung von Beziehungen zwischen Objekten auf entsprechenden Datenbank-Relationen.
Da, wo früher nur eine geringe Anzahl von Dateneinträgen notwendig war, wird heute mit einer riesigen Fülle an Informationen und Daten gearbeitet, was die (Datenbank-)Abfragezeiten im Laufe der Zeit immer mehr erhöht. Die Anforderung an Hibernate ist ganz klar: Eine möglichst intelligente Datenbankabfrage, die zu einer besseren Performance führt. Und wie läuft das genau ab?
Vordefinierte Reihenfolge und Gesamtzahlenabfrage & Hibernates smarte Annahmen
Es ist naheliegend, dass man in JPA/Hibernate Pagination mit .setFirstResult und .setMaxResults und somit mit einer vordefinierten Reihenfolge und einer Gesamtanzahlabfrage arbeitet.
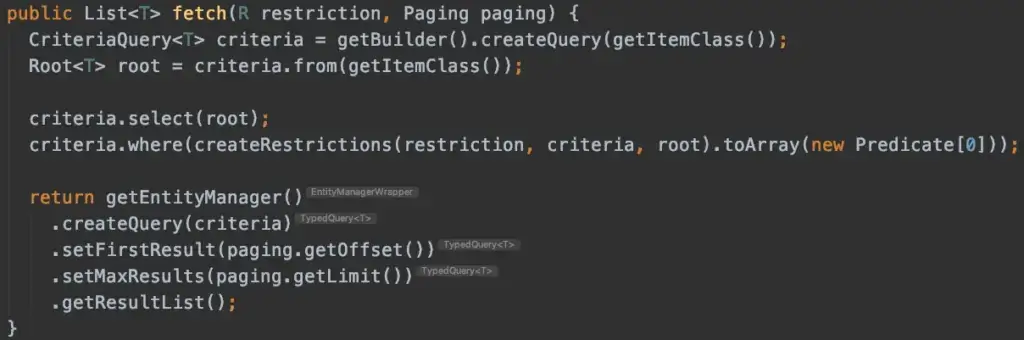
Doch der Teufel liegt hier im Detail.
Wusstest Du schon, dass Hibernate unter der Haube automatisch zwischen Pagination via Datenbankabfrage (schnell) oder Pagination via In-Memory-Filterung (langsam) unterscheidet?
Richtig, Hibernate trifft hier automatisch durchaus smarte Annahmen anhand der zu erzeugenden Abfrage. Entscheidungen, die durchaus massiv die Performance der Datenbankabfrage beeinflussen.
Hibernate und die smarte Pagination-Annahme – Ein Beispiel
Nehmen wir mal an, es wird eine Auflistung von Unternehmen benötigt, zu der man unmittelbar eine Unterauflistung der Mitarbeiter beider Unternehmen haben möchte.
Unternehmen
| 23 | Unternehmen A |
| 42 | Unternehmen B |
Mitarbeiter
| 1 | Jörg |
| 3 | Andreas |
| 5 | Claudia |
Nun kannst du unterschiedliche Strategien fahren:
Eager-Loading:
Ich lade zusammen mit dem Unternehmen gleich alle zugehörigen Mitarbeiter
Wird etwas „eager“ geladen (bspw. auch Annotationen, Fetch-Graphen etc.), dann erkennt Hibernate das und schaltet automatisch auf Pagination via In-Memory-Filterung um. Anstatt die Daten in SQL zu beschränken, werden die kompletten Daten In-Memory geladen und dann gefiltert/verworfen.
Lazy-Loading:
Ich lade Unternehmen und Mitarbeiter getrennt voneinander
Wenn ich dagegen „lazy“, also möglichst beschränkt auf eine Datenbanktabelle, arbeite, dann generiert Hibernate entsprechendes Offset-Limit innerhalb der Datenbank und es werden nur die Daten geladen, die benötigt werden.
Warum tut Hibernate das?
Bleiben wir bei dem Beispiel von vorhin. Wir haben eine Liste zweier Unternehmen. Lädt man Unternehmen A, dann ist das OFFSET 0 und LIMIT 1, bei Unternehmen B wäre es dann folglich OFFSET 1 und LIMIT 1.
Was passiert, wenn man nun die Mitarbeiter dazu nimmt? Dann erzeugt die Datenbank folgendes Ergebnis:
| 23 | Unternehmen A | 1 | Jörg |
| 23 | Unternehmen A | 3 | Andreas |
| 23 | Unternehmen A | 5 | Claudia |
| 42 | Unternehmen B | NULL | NULL |
Genau hier zeigt sich das Problem. Vorher war das LIMIT immer gleich der Anzahl von Unternehmen. Nun ist sowohl OFFSET 0 und LIMIT 1 Unternehmen A, wie auch OFFSET 1 und OFFSET 2, während OFFSET 3 nun Unternehmen B wäre. Es gibt kein allgemeingültiges Schema mehr, wo ein Unternehmen anfängt und aufhört. Hibernate kann also kein Pagenation via SQL machen, das Ergebnis ist nun, dass Hibernate alles lädt und dann filtert. Wenn nun die Liste von Unternehmen nicht 2, sondern >10.000 ist, macht das einen massiven Unterschied.
Unser Tipp? Bei Pagination möglichst „lazy“ zu arbeiten und weitere benötigte Daten via Postfetching innerhalb der Transaktion zu laden oder nachgelagert abzufragen.
Und wer noch nicht weiß, ob er betroffen ist, kann mit folgendem Konfigurationsparameter in seiner persistence.xml Hibernate schlicht verbieten, den langsamen Ansatz zu verwenden.
hibernate.query.fail_on_pagination_over_collection_fetch
Hast du noch Fragen? Schreib´s uns in die Kommentare!



Feedback